前言
一开始只是在寻找文本分类相关的论文,在浏览了大量的论文之后发现CNN和RNN逐渐成为这几年NLP的主流模型,于是打算深入了解一下这个方面的应用。
自从2013年Google关于词嵌入(word embedding)的工作出来之后,利用word embedding作为模型输入变成了一种常用的文本预处理。与此同时,CNN(卷积神经网络)在计算机视觉(CV,computer vision)取得了非常好的成绩,这很自然地让人想到可以将卷积操作应用在词嵌入矩阵上,自动提取特征来处理NLP的任务。就笔者个人感觉来看,2014和2015年关于CNN应用在NLP上的论文数量突增,仿佛雨后春笋般成为了当时的研究热点。本文选取了其中几篇比较有代表性的进行介绍。
什么是CNN?
计算机视觉
CNN全称Convolutional Neural Network,中文名卷积神经网络,由于在计算机视觉相关的任务上表现优异而得到了研究人员的青睐。考虑一个图片和它的矩阵表示(一般情况下会将图片表示为 的矩阵,其中的3表示3个输入channel,分别为RGB,对应0-255范围的整数。下图是一个假设的简化描述 )


卷积神经网络的能力在于,能通过神经网络的训练自动地识别图中的特征(比如图中的建筑,也就是矩阵中1的部分),提取这些特征的过程就叫做卷积。
卷积操作
下图展示了一个图片的矩阵表示和一个卷积核(filter)的表示

卷积的过程,就是图像中的一部分和卷积核进行element-wide的乘法然后将结果加起来得到一个结果(特征)。我们来看一下例子:
图中我们选定了一个3x3的卷积窗口(这个窗口和卷积核的大小是一致的),对其进行了点乘并将结果矩阵求和之后得到了feature map的第一个数字。我们接下来看第二个例子

依然是刚刚的图片,但是卷积窗口向右移动了一格,我们把移动的格子数叫做步幅(stride),步幅的大小会影响feature map的大小,如图中表示的就是stride为1的情况。可以推知,feature map剩下的元素也是按照这种方式计算的。

让我们回到刚刚的问题,卷积操作为什么可以提取特征?
一种直观的理解是,filter本身是一个特征检测器,在需要检测的部分会有更加大的数值,比如上面例子中的filter可以看做是在检测图片的片段中是否存在一个X形状。类似的,如果要检测一个图片片段是否有一条直线,那么filter的形式可能是有一行是远大于0而另外的数值接近0的矩阵。
值得注意的是,filter的值都是在神经网络的训练中学习到的,人为设置的超参数只有filter的大小,步幅等,因此卷积是一个自动提取特征的操作。
池化(Pooling)
池化的目的是提取一个特征池(类似于卷积核一样的窗口)中的总特征(或者最重要的特征),可以大大减少特征的数量,减少无关特征的干扰。在NLP的任务中还担任了处理边长输入的角色(在下文会进一步讲解)。
最常见的池化是Max-Pooling,即在一个窗口中选择最大的数值作为结果,计算方式如下
可以看到,pooling窗口的大小是2x2,stride是2,相当于把输入的矩阵分成四块,每一块取出最大的数值作为新的feature map的值。
关于Pooling的解释,个人理解是提取了更高维的同类特征,比如有四个卷积核分别提取了上箭头,下箭头,左箭头和右箭头的形状,那么max-pooling就相当于提取了“箭头”这个特征。
一些其它的Pooling还有average-pooling和min-pooling等,具体操作视应用而定。
激活函数ReLU
一般神经网络的激活函数都是sigmoid或者tanh,但是在CNN中一般应用的是被称为ReLU的函数,其形式非常简单
之所以选择这个激活函数,一方面是计算上的便捷,另一方面是这个函数可以很好地处理梯度消失的问题。关于梯度消失的相关内容不在本文的介绍范围内。
对于介绍CNN在NLP中的应用,CNN的理解到这里就已经差不多了,想要进一步了解CNN的可以去查看附录的参考资料。
CNN在NLP中的应用
注意:以下内容并不按照论文发表的时间进行排列
一种直观的迁移(Rie Johnson’s Paper)
原论文:Effective Use of Word Order for Text Categorization with Convolutional Neural Networks
这个论文提出的模型可以看做是非常直观的从图像到文本的迁移。论文使用了multiple channel的文本one-hot输入,将每一个单词当成一个像素,每一个channel对应一个单词one-hot向量中的一个维度,模拟了图像的RGB输入。之后对其输入进行了简单的卷积核池化,最后加上全连接层来产生结果。
输入部分
对于一个字典V = {'don't ,hate ,I ,it ,love '},句子”I love it”的对应的one-hot向量分别为[0 0 1 0 0],[0 0 0 0 1],[0 0 0 1 0],输入的句子向量为,其中one-hot向量的每一个维度都对应着一个channel,输入的句子向量是one-hot向量的堆叠。
卷积部分
这部分中论文提出了两种模型,Seq-CNN和bow-CNN
Seq-CNN的卷积操作输入(称为region)是k个单词one-hot的连接,比如时,输入分别是”I love”的连接和”love it”的连接,表示如下: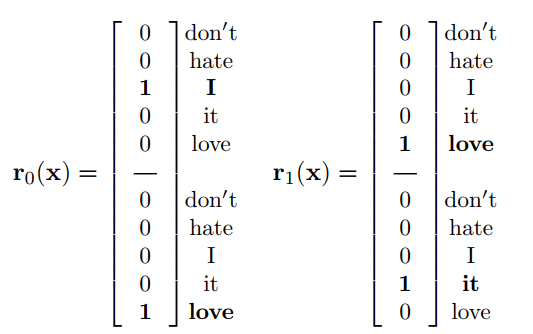
有了region之后,对每一个region进行一个的操作(卷积)来产生下一层的feature map。Seq-CNN有一个显而易见的缺点:当k变大时,一个region的长度会急剧增长,导致整个模型的训练参数大大增加,训练的开销极大。虽然这个模型保留了词语的输入顺序信息,但是在实际中并不可行。因此有了另一个折中方案Bow-CNN
Bow-CNN的输入不一样的地方在于,它压缩了所有词语的one-hot向量为一个,最后变成了类似于词频向量的表达,如图所示: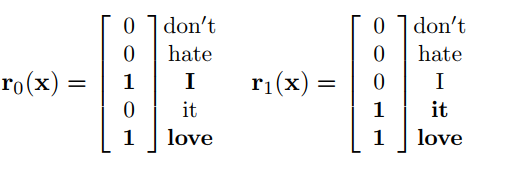
这样的表示使得region的长度固定为词库的大小,但是损失了k个词语之间的顺序关系,是一种介于n-gram和seq-CNN的模型。
Pooling部分
论文中的模型没有固定使用一种pooling方案,而是采用了多种pooling,包括max-pooling和average pooling。具体使用了哪一种pooling根据实验设置的不同而不同。
实验部分
实验的结果如图所示: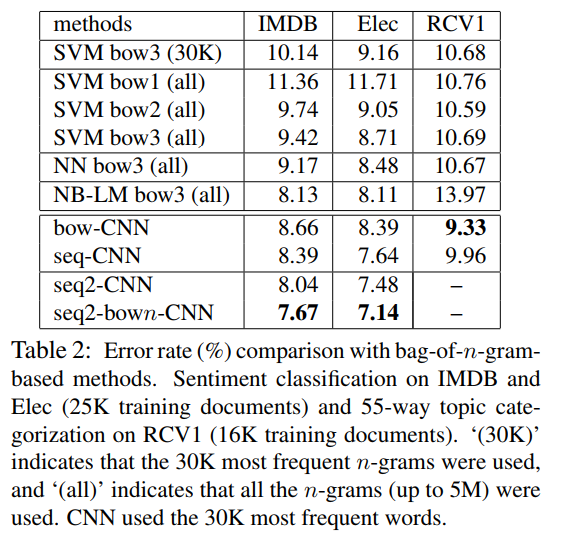
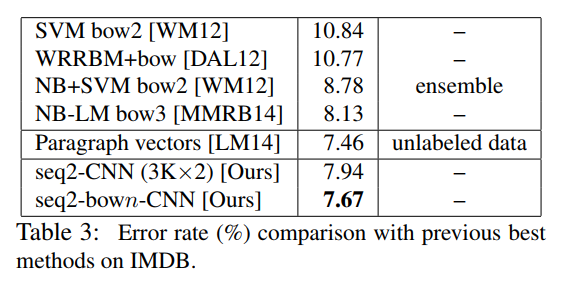
可以看到,相比于传统的NLP模型,论文提出的CNN有着显著的优势。提出来的模型简单易行,有不错的成绩,但是在计算的开销并不能忽视,而开销小的方案不可避免地会丢失一部分词序信息。
使用预训练词向量的baseline(Kim Y’s paper)
原论文:Convolutional neural networks for sentence classification
模型概览:
这篇论文提出的模型非常简洁,使用了Google公开的基于Google news训练的词向量,在各个数据集上面取得了相当好的成绩,成为之后很多论文的baseline。
输入部分
模型的输入采用了Google的word embedding,在实现上首先将句子编码成index向量,然后index向量输入到embedding层,通过一个lookup table寻找到对应的embedding,组成输入矩阵。在论文中,embedding层的初始化包括了随机初始化,使用Google word embedding初始化,在更新参数的时候,不改变embedding(即不通过back propagation来更新embedding层的参数)的叫做static模型,而更新embedding的叫做non-static(每次更新一部分embedding),这实际上是一个fine-tune的过程,能够让预训练的模型更加贴近当前的任务。
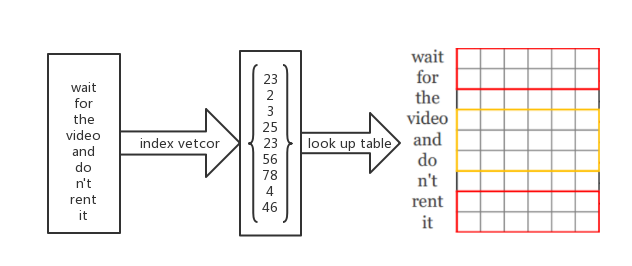
卷积部分
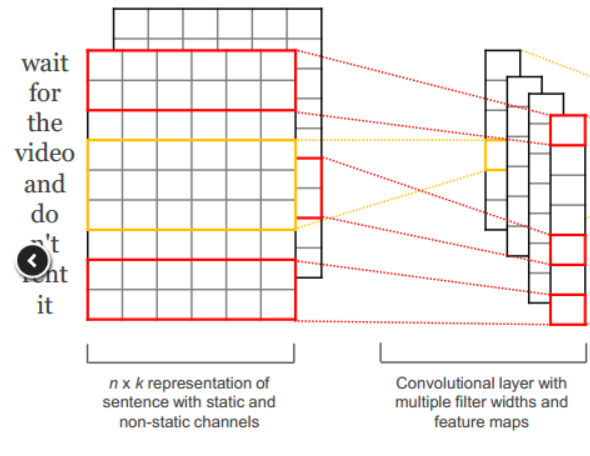
得到输入的句子矩阵(由每一个词语的word embedding堆叠而成)之后,对大小为k个词语的窗口进行卷积操作,即word embedding的长度为m,窗口大小为k,则filter的大小为。论文中同时使用了的filter,每一种filter各100个,因此会产生300个feature map,有效地捕捉了各个方面的特征。
Pooling部分
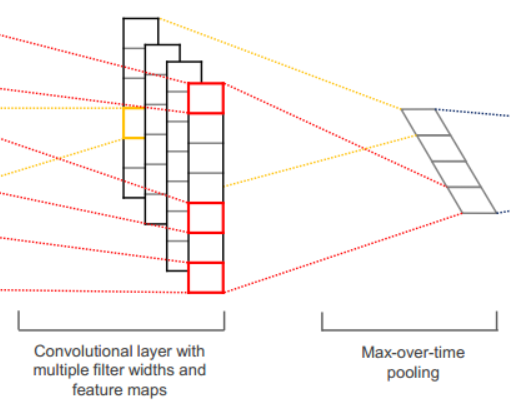
这个部分使用了最常见的max-pooling,在文中被称为max-over-time-pooling,因为这个pooling操作直接针对每一个feature map,提取出每一个feature map的最大值,组成一个300维的pooling feature。这样做有一个巨大的好处:可以处理变长的句子。回想一下,句子长度为n个词语时,对于窗口大小为k的filter,会产生个feature,即每一次的输入都会产生不同长度的feature map。max-over-time-pooling直接针对feature map操作,有效地处理了不同feature map大小不一样的问题。
Drop-out和全连接层
最后的结果是通过将pooling的结果和一个全连接层相连进行计算得到的,如果是分类问题,那就再末尾加一个softmax层来得到每一个类别的概率。论文中引入了一个叫做drop-out layer的模块,如字面意思描述,这个层会把一些信息直接丢掉,这个丢失概率p是人为设置的,一般为0.5.这个层能够有效地防止过拟合,被证明是有效的正则化方式。
实验部分
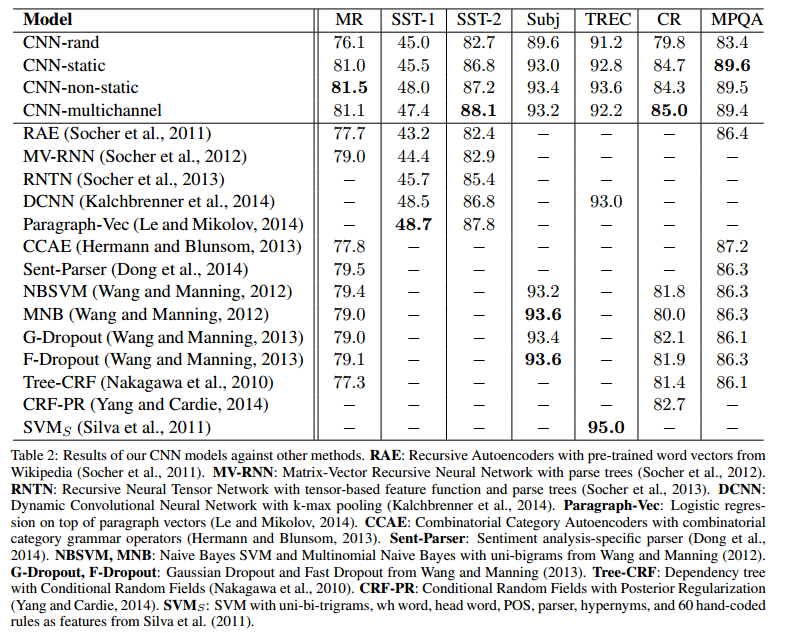
实验的结果如图所示,测试的论文模型主要是随机初始化、word embedding初始化、static模型、non-static模型的组合。可以看到论文提出来的模型在三个数据集上取得了最好的成绩,其它数据集的表现达到了state-of-art的水平。
另外一些有趣的发现如下: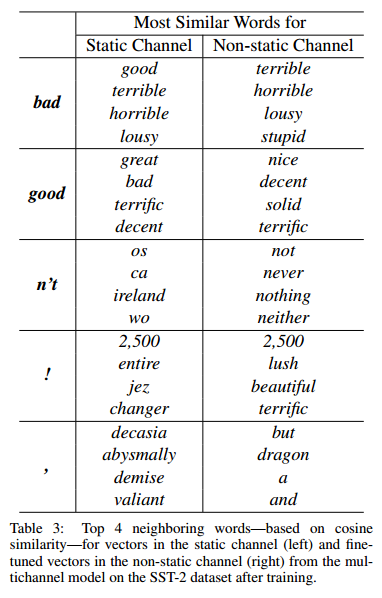
这个表格列出了static和non-static模型中的相近词,最左列是目标,第二列是static模型(原来的word embedding)中和目标词最相近的embedding,第三列是non-static的情况。可以看到,原来的word embedding没办法捕捉反义词的区别(因为good和bad的上下文通常很类似),而经过fine-tune之后,词向量更加好得贴近了当前任务(情感分析),因此有了更加理想的相近词向量。
这个论文提出来的模型具有很强的可应用性,并且同时证明了Google的word embedding具有很不错的泛用性。
动态池化的引入(Kalahbrenner’s paper)
原论文:A convolutional neural network for modelling sentences

这篇论文的主要贡献在于提出了一种max-pooling的推广形式k-max-pooling,即在pooling的时候选取前k个最大的,同时会保留这k个最大的值的相对位置,一定程度上保留了位置信息,同时能够更好地捕捉到特征。dynamic-k-max-pooling是一个进一步的推广,k是一个句子长度的函数,可以随着句子的长度而改变k的值,从而适应更远的联系。
输入部分
这个模型的输入部分没有特别之处,和上一篇论文的一样都是讲句子转化为word embedding的表示方法。初始化采用的是随机初始化。
卷积部分
这个模型提出了一种叫做宽卷积的卷积操作。
图中上方的点是卷积结果,下方的点是输入。左图使用窄卷积,一个卷积核覆盖五个输入点。右图使用宽卷积,一个卷积核覆盖四个输入点。
传统的卷积操作会将卷积窗口的开始位置定在输入的开头处,这样子卷积结果的长度会比输入小。而宽卷积允许卷积窗口越过输入的边界,超出的部分用0来填充,相当于在输入的两端加上额外的0再进行卷积。这样子可以更好地捕捉边缘特征。
Pooling部分
模型中使用了非常多的pooling层,其中包括了k-max-pooling和dynamic-k-max-pooling

- k-max-pooling:每次从pooling层的输入中选取k个最大的值,按照其相对词序保存下来作为pooling的结果。
- dynamic-k-max-pooling:和k-max-pooling类似,但是这里的k不是人为设置的,而是根据句子的长度来确定的。计算公式:其中,是人为设置的最顶层pooling的k值,L是总的卷积层,l是当前的卷积层,s是句子的长度。
例子:3个卷积层,,第一个pooling的,
Folding和全连接
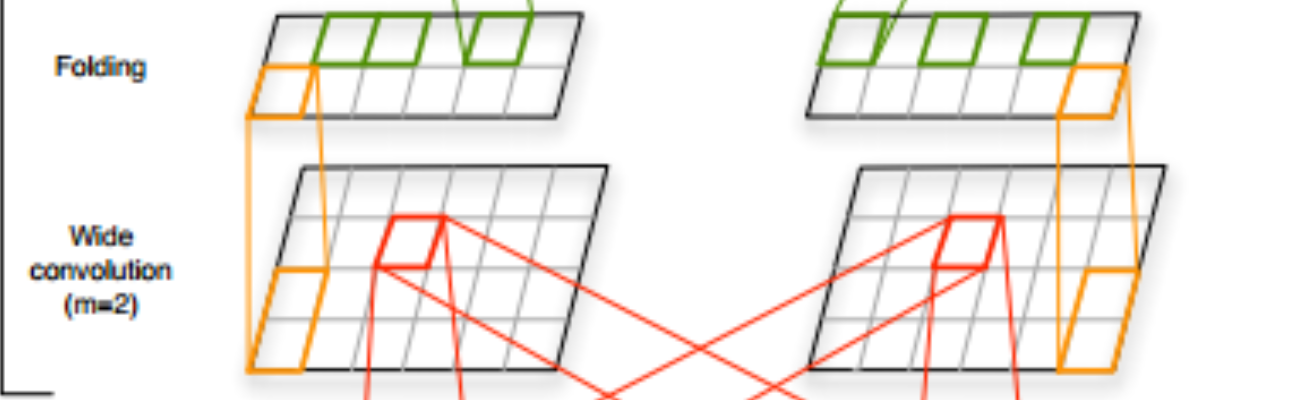
Folding操作是把两行数据直接加起来变成一个新的行,这样子能够添加行与行之间的关联。
在模型的最后依然是通过一个softmax层来产出结果。
实验部分
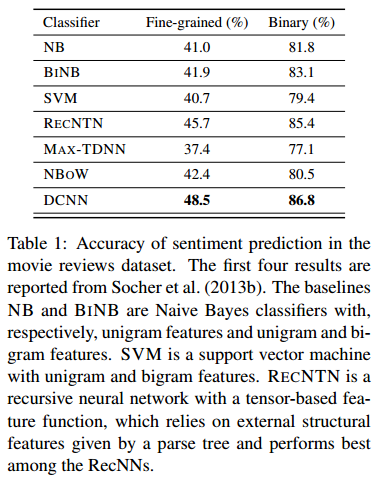
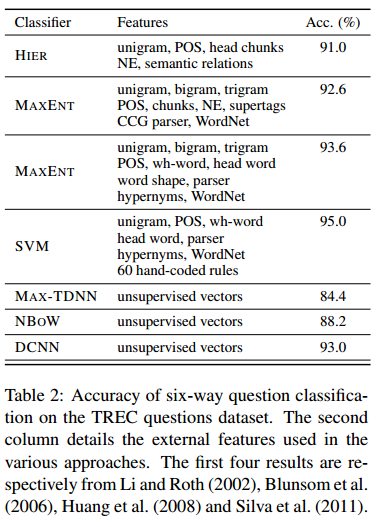
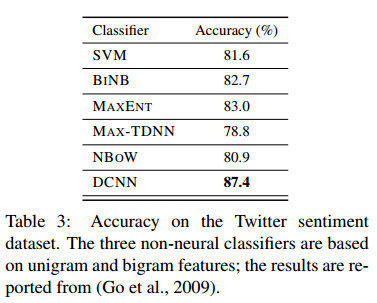
可以看到论文提出的DCNN的表现对于传统的模型来说有着非常大的提高。
字母级别的输入(C´ıcero Nogueira dos Santos’ Paper)
原论文:Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts
这篇论文的主要创新点在于,输入部分的word embedding采用的是普通word embedding+character embedding的拼接。之所以采用字符级别的输入,是为了能够捕捉到词缀和词根的信息并加以组合(字符级别的输入在处理句子成分标记的RNN中特别有效,因为-ly往往意味着副词而-ment是常见的名词词缀)。这样子有利于建立更加完善的语义模型。模型概览如下,主要部分是输入部分的embedding层。
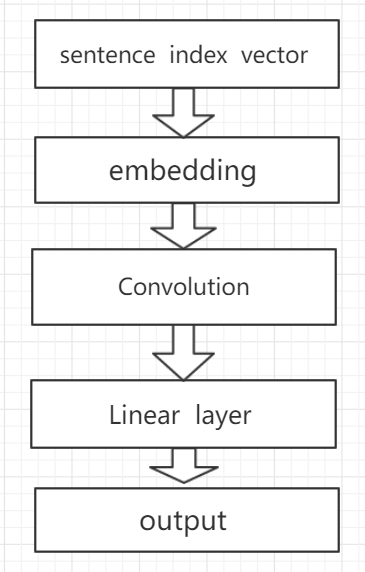
输入部分
输入的embedding分为两个部分,word embedding和character-level embedding,这两种embedding使用不同的网络结构产生,最后拼接到一起作为输入。
word embedding:和普通的word embedding别无二致,计算公式:
其中是模型参数而是一个词语的ont-hot表示。
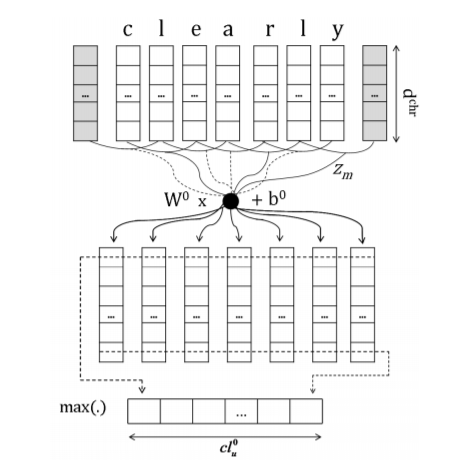
character-level embedding:给定一个词语w,其单词序列为.首先把每一个字母转化为独立的字母embedding(实际上是把字母看做是单词):
其中是模型参数而是一个字母的ont-hot表示。
接着,把字母向量排列起来组成一个由字母向量组成的单词矩阵,对这个矩阵进行卷积操作。具体地说,先把k个连续的字母向量拼接成一个长长的卷积region:,然后对这个向量进行卷积操作:
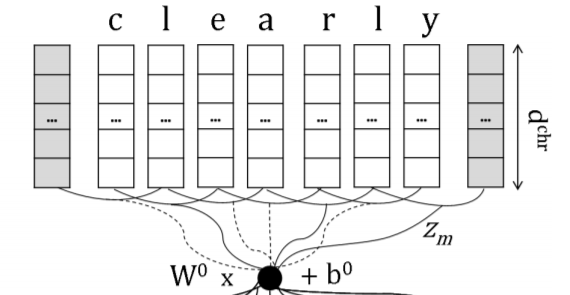
紧接着对卷积的结果进行一个max-over-time的pooling操作,使得不同长度的单词可以被编码到相同的长度: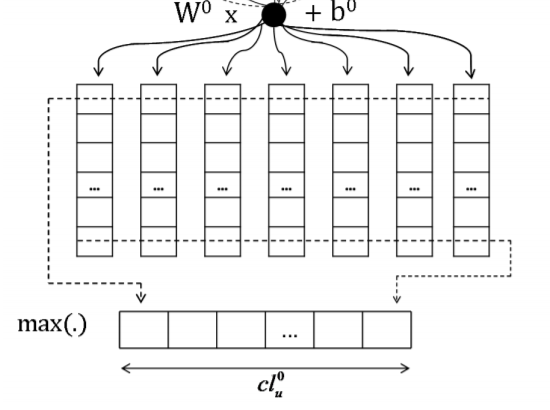
至此,我们获得了单词的词向量和字母表示的向量,输入为两者的连接
其他部分
对于由词向量组成的句子输入矩阵,模型先是采用了上文类似的卷积操作,然后加上了一个全连接层和一个softmax层来产生分类概率。这部分并无特别的创新之处。
实验部分
实验结果如下图:
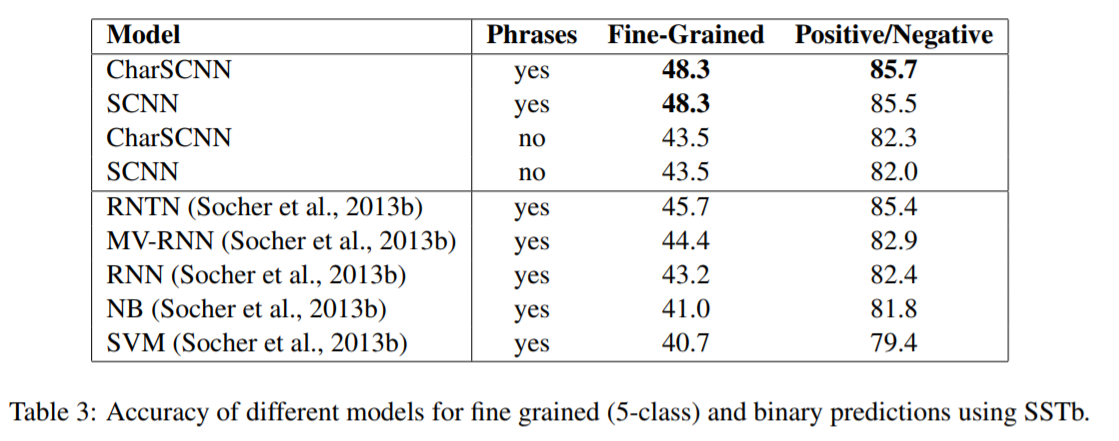
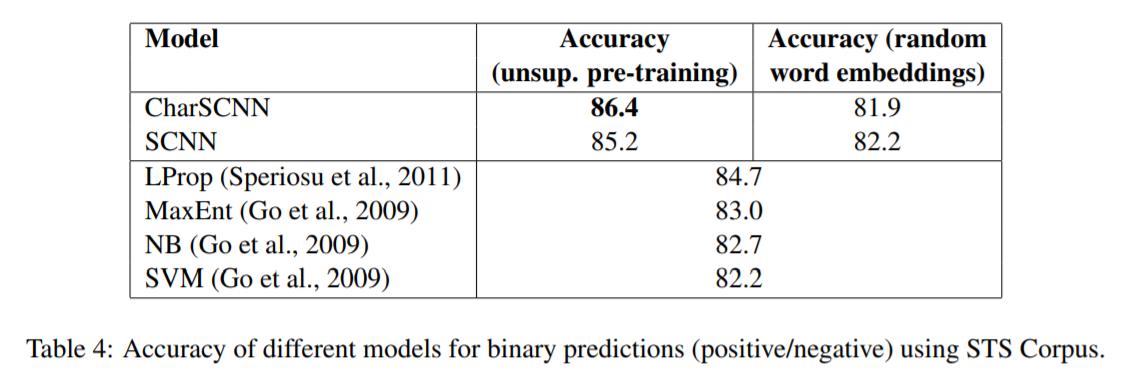
其中CharSCNN是采用了word embedding+character embedding的输入,SCNN只采用了word embedding.可以看到字符级别的输入对于性能的提高有着巨大的贡献。
附录
本文英文版PPT的overleaf地址:https://www.overleaf.com/read/xbyqgvwqcgpj
参考资料
[1]零基础入门深度学习(4) - 卷积神经网络
[2]卷积神经网络(CNN)在句子建模上的应用
[3]Understanding Convolutional Neural Networks for NLP[1]和[3]都是非常好的CNN入门资料,[2]是一个比较详细和到位的CNN在NLP上的应用总结